Algorithms To Live By: The Computer Science of Human Decisions — Book Summary and Notes
What if we applied computer science to decision-making in everyday life? An algorithm is not just a series of steps used to solve computing problems, but rather it provides a better standard to compare human cognition itself.
- Optimal Stopping: Teaches us when to look and when to leap for an opportunity.
- The Explore/Exploit Tradeoff: Teaches us how to find the balance between trying new things and enjoying our favourites.
- Sorting Theory: Teaches how to arrange our workspace.
- Caching Theory: Teaches us how to fill our closets.
The notion of human algorithm design provides a new vocabulary for the world around us and a chance to learn something truly new about ourselves.

Algorithms To Live By
The Computer Science of Human Decisions By Brian Christian & Tom Griffiths
Optimal Stopping
When to Stop Looking
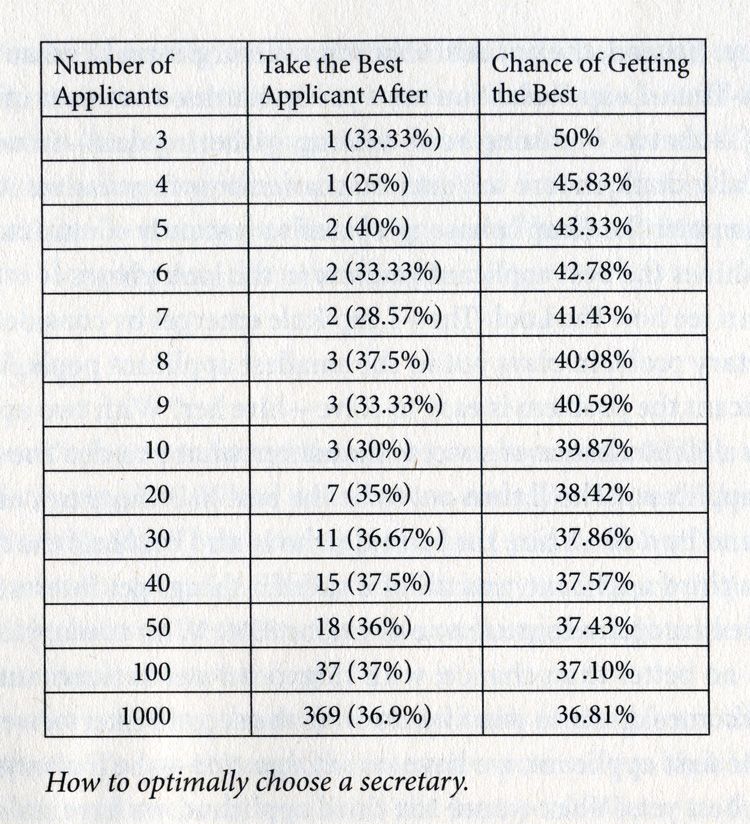
Imagine you’re interviewing a set of applicants for a job position, and your goal is to maximize the chance of hiring the single best applicant in the pool. While you have no idea how to assign scores to individual applications, you can easily judge who you prefer in ranked order (oridinal numbers). You can decide decide to offer the job to an applicant at any point and they are guaranteed to accept it, termination the search. But if you pass over an application, they are gone forever.
In any optimal stopping problem, the crucial dilemma is not which option to pick, but how many options to even consider. In your search for the best applicant, you may fail in two fails: stopping too early or stopping too late. If you stop too early, you leave the best application undiscovered; if you stop too late, you miss out on the best applicant. However, simply being the “best applicant so far” is insufficient because, for example, the very first applicant is the best so far by definition. Thus, as the number of interviews increase, the rate at which we counter the “best application so far” decreases.
The optimal solution takes the form of a Look-Then-Leap Strategy. You set a predetermined time for “looking” (to gather data) in which you hire no applicants no matter how impressed you are. After that point, you enter the “leap” phase and immediately hire anyone who outshines the best application within the “looking” phase. Mathematically, the exact place to draw the line between looking and leaping is 37% of the pool (The 37% Rule).
Explore or Exploit
The Latest v.s. The Greatest
Should we try new things or stick with our favorite ones? We intuitively understand that life is a balance between novelty and tradition, taking risks and staying in our comfort zone, but to what balance? In computer science, exploration is gathering information and exploiting is using the information you have to get a good known result.
In the popular television show Deal or No Deal, a contestant chooses one of twenty-six briefcases, which contain a cash prize from a penny to a million dollars. As the game progresses, the Banker will periodically call in and offer the contestant a sum of money to not open the chosen briefcase. For every briefcase we know little or nothing about, there is some guarantee that the payout will make us content enough to not care about the remaining options. This number, known as the Gittins Index, suggest an obvious strategy in the Casino: always play the slot machine with the highest index.
The Gittins Index provides a rigorous justification for preferring the unknown given that we have some opportunity to exploit the results of what we learn from exploring. The old saying tells us that “the grass is always green on the other side of the fence,” but the math tells us why: the unknown has a chance of being better, even if we actually expect it to be no different, or if it’s just as likely to be worse. The untested rookie is worth more than the veteran of seemingly equal ability, precisely because we know less about him.
Computer science can’t offer you a life with zero regret, but it can potentially, offer you a life with minimal regret. In the memorable words for management theorist Chester Barnard: “To try and fail is at least to learn; to fail to try is to suffer the inestimable loss of what might have been.”
Sorting
Making Order
Sorting something that you will never use is a complete waste; searching something you never sorted is merely inefficient. The questions lies in how to predict which items are most likely to be used in the future.
Bubble sort + Insertion sort — are the most common, least efficient sorting, when you put the book in alphabetically against a shelf of books, there is a billion different permutations and options.
Merge sort — is the next best thing, when you compare two sets against each other and sort each time, then compare them against the next set.
Bucket sort — is the most efficient, fastest way of a ‘close’ enough solution, putting things into buckets/classifying — of course that depends how well you choose your buckets.
Single elimination — is a terrible way to rank, that is, e-sports teams — all it tells you is the 1st place, but all other places in the ranking are not truly representative.
Round robin — gives you full information, but also requires the most effort as everyone plays everyone.
Bracket tournaments — are the most efficient way of ranking, they are a combination of a bucket- and merge sort.
Caching
Random eviction — is actually not half bad, as the most important things keep getting back in
First In, First Out (FIFO) — it’s essentially a queue kicking the oldest things out of the memory
Least Recently Used (LRU) — evicting the item that’s gone the longest untouched (a pile of papers on your desk is an efficient way of organising paper if you put the latest always on top)
Ideally, you have a couple different caches which are organised by category, so you shorten the path of access and don’t have to wade through all information every time.
In A Nutshell
Outcomes make news headlines — indeed, they make the world we live in — but processes are what we have control over. Sometimes ‘good enough’, really is good enough. Up against hard cases, effective algorithms make assumptions, show of bias toward simpler solutions, trade off the costs of error agains the cost of delay, and take chances. These aren’t the concessions we make when we can’t be rational. They’re what being rational means.